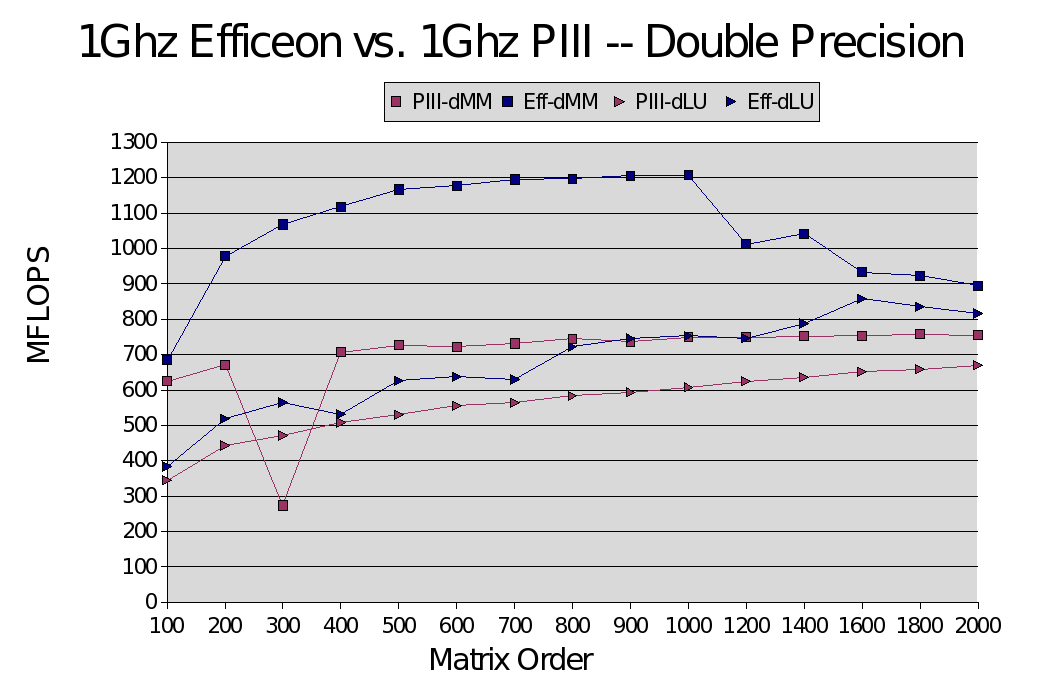
OK, the PIII has 1/2 the double precision theoretical peak of the Efficeon (thanks to SSE2), and we can see that, particularly in the early part of the DGEMM curve (ignore the PIII performance dive at 300; it's just a timing artifact). There are several questions here. The first question might be, why does DGEMM only get around 60% of peak, since the P4 (not shown here) gets well above that? Transmeta's code morphing software (CMS) does not seem to do as good a job as Intel's hardware on register renaming and out of order execution, both of which are required for good FP performance when you have only 8 registers, and a fp pipe of length 8! I had to software pipeline (as much as you can with only 8 regs) this code just to get this performance.
Another question: why does LU get so much less percent of GEMM, and why does GEMM performance trail off? I believe both are explained by the CMS. Translated instructions are cached in the L1 & L2. For large problems, the instructions and data for GEMM fight for the L2, and so we are constantly reinterprating the GEMM code. For LU, you do a bunch of extra stuff, and so again, the CMS keeps us from getting good performance.
We have the same essential stuff for single precision:
