All routines except SYMV call the GEMV kernel in the same fashion.
Other than SYMV, all routines cannot reduce the load of 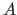 from
from 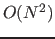 ,
but can reduce the memory access of both
,
but can reduce the memory access of both  and
and 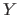 from to
from to
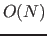 . In general, the access is reduced by register blocking in
the GEMV kernel. Therefore, the higher level routines block such
it is reused across kernel invocations in L1 (if you write a axpy-based
notranspose GEMV kernel, is blocked instead of ). What this amounts
to is partitioning via:
. In general, the access is reduced by register blocking in
the GEMV kernel. Therefore, the higher level routines block such
it is reused across kernel invocations in L1 (if you write a axpy-based
notranspose GEMV kernel, is blocked instead of ). What this amounts
to is partitioning via:
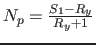 , where
, where 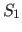 is the size, in elements,
of the Level 1 cache,
is the size, in elements,
of the Level 1 cache, 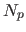 is the partitioning of , and
is the partitioning of , and 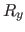 corresponds
to the Yunroll of your input file. The equation is actually a little
more complicated than this, as ATLAS may want to use less than the full
to avoid cache thrashing and throwing useful sections away between
kernel calls. However, this gives the user some idea of the importance of
these parameters. In particular, it shows that Yunroll should not
be allowed to grow too large, for fear of causing the loop to be
too short to support good optimization.
corresponds
to the Yunroll of your input file. The equation is actually a little
more complicated than this, as ATLAS may want to use less than the full
to avoid cache thrashing and throwing useful sections away between
kernel calls. However, this gives the user some idea of the importance of
these parameters. In particular, it shows that Yunroll should not
be allowed to grow too large, for fear of causing the loop to be
too short to support good optimization.
Also, note that after the first invocation of the kernel, will come
from L1, leaving the dominant data cost.
At present, SYMV does a different blocking that blocks both and
(all other routines block only one dimension), so that is reused
between calls to the Transpose and NoTranspose kernels. This may
eventually change as greater sophistication is achieved (as you might
imagine, you get two very different GEMV kernels if one is expecting
from main memory, and the other expects to come from L1, as
in this case; this means we may at some time generate a specialized
L1-contained GEMV kernel).
Note that the 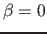 case must not read , since the memory may
legally be unitialized.
case must not read , since the memory may
legally be unitialized.
Clint Whaley
2012-07-10